Si leíste la Parte 1 de esta guía, ya diste el primer paso. Tienes tests. Corren. Tu equipo lo sabe.
Pero ahora tienes 20, 30, 50 tests… y empezaste a notar algo:
- El código se repite en todos lados
- Cambiar un selector rompe 15 tests a la vez
- No sabes cómo integrar tus tests al pipeline del equipo
- Sientes que escribes tests, pero no diseñas una estrategia
Si te identificas con esto, estás exactamente donde necesitas estar para dar el siguiente salto.
Escribir tests te hace QA que automatiza. Organizar esos tests para que escalen te hace QA que piensa en arquitectura.
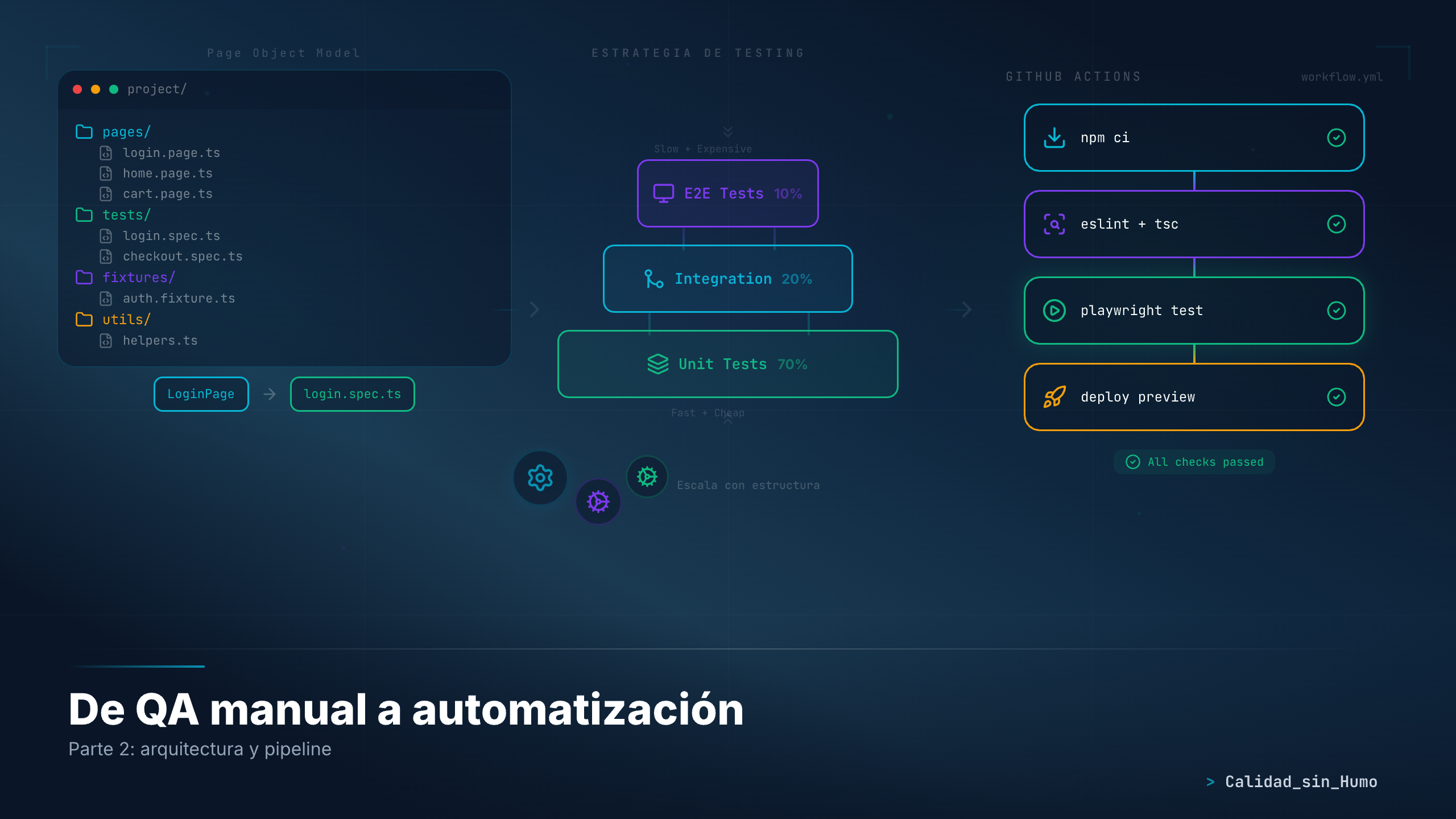
1. Arquitectura: Page Object Model (y por qué tu código actual no escala)
Cuando tienes 5 tests, poner todo en un solo archivo funciona. Cuando tienes 50, es un desastre.
El problema se ve así:
// test-1.spec.tsawait page.getByLabel("Email").fill("user@test.com");await page.getByLabel("Contraseña").fill("Pass123");await page.getByRole("button", { name: "Iniciar sesión" }).click();
// test-2.spec.ts — exactamente lo mismoawait page.getByLabel("Email").fill("user@test.com");await page.getByLabel("Contraseña").fill("Pass123");await page.getByRole("button", { name: "Iniciar sesión" }).click();
// test-3.spec.ts — y otra vezawait page.getByLabel("Email").fill("user@test.com");await page.getByLabel("Contraseña").fill("Pass123");await page.getByRole("button", { name: "Iniciar sesión" }).click();El día que el equipo de frontend cambie “Iniciar sesión” por “Entrar”, tienes que modificar 30 archivos. Eso no es automatización. Es mantenimiento manual del código de automatización. Irónico, ¿no?
La solución: Page Object Model
POM no es un patrón complicado. Es sentido común organizado: agrupa los selectores y acciones de cada página en una clase. Así, si algo cambia en la UI, lo cambias en un solo lugar.
import type { Page, Locator } from "@playwright/test";
export class LoginPage { private readonly emailInput: Locator; private readonly passwordInput: Locator; private readonly submitButton: Locator;
constructor(private readonly page: Page) { this.emailInput = page.getByLabel("Email"); this.passwordInput = page.getByLabel("Contraseña"); this.submitButton = page.getByRole("button", { name: "Iniciar sesión" }); }
async goto() { await this.page.goto("/login"); }
async login(email: string, password: string) { await this.emailInput.fill(email); await this.passwordInput.fill(password); await this.submitButton.click(); }}import { test, expect } from "@playwright/test";import { LoginPage } from "../pages/login.page";
test("login exitoso redirige al dashboard", async ({ page }) => { const loginPage = new LoginPage(page); await loginPage.goto(); await loginPage.login("admin@empresa.com", "Password123");
await expect(page.getByRole("heading", { name: "Dashboard" })).toBeVisible();});
test("login con credenciales inválidas muestra error", async ({ page }) => { const loginPage = new LoginPage(page); await loginPage.goto(); await loginPage.login("admin@empresa.com", "contraseña-incorrecta");
await expect(page.getByText("Credenciales inválidas")).toBeVisible();});La estructura de carpetas que recomiendo
tests/├── pages/ # Page Objects│ ├── login.page.ts│ ├── dashboard.page.ts│ └── users.page.ts├── fixtures/ # Fixtures personalizados│ └── test-fixtures.ts├── login.spec.ts # Tests por feature├── dashboard.spec.ts└── users.spec.tsLas assertions (los expect) van en los tests, no en los Page Objects. Los
Page Objects son acciones y selectores. Los tests son las verificaciones. Si
mezclas ambos, pierdes claridad sobre qué está validando cada test.
El siguiente nivel: fixtures personalizados
Cuando te canses de escribir const loginPage = new LoginPage(page) en cada test, Playwright te permite crear fixtures — objetos que se crean automáticamente antes de cada test y se destruyen después.
import { test as base } from "@playwright/test";import { LoginPage } from "../pages/login.page";import { DashboardPage } from "../pages/dashboard.page";
type MyFixtures = { loginPage: LoginPage; dashboardPage: DashboardPage;};
export const test = base.extend<MyFixtures>({ loginPage: async ({ page }, use) => { const loginPage = new LoginPage(page); await use(loginPage); },
dashboardPage: async ({ page }, use) => { const dashboardPage = new DashboardPage(page); await use(dashboardPage); },});
export { expect } from "@playwright/test";import { test, expect } from "../fixtures/test-fixtures";
test("login exitoso redirige al dashboard", async ({ loginPage, page }) => { await loginPage.goto(); await loginPage.login("admin@empresa.com", "Password123"); await expect(page.getByRole("heading", { name: "Dashboard" })).toBeVisible();});Cada test recibe su propia instancia del fixture. Aislamiento total. Sin estado compartido. Sin colisiones.
2. CI/CD: tus tests en el pipeline (donde realmente importan)
Un test que solo corre en tu máquina es un test a medias. El verdadero valor aparece cuando tus tests corren automáticamente cada vez que alguien hace push o abre un pull request.
Si nunca configuraste CI/CD, esto te va a parecer intimidante. Pero te prometo que es más simple de lo que crees.
GitHub Actions: tu primer pipeline
Crea este archivo en tu repositorio y tus tests correrán automáticamente en cada push:
name: Playwright Testson: push: branches: [main, develop] pull_request: branches: [main]
jobs: test: timeout-minutes: 60 runs-on: ubuntu-latest steps: - uses: actions/checkout@v5 - uses: actions/setup-node@v6 with: node-version: lts/* - name: Install dependencies run: npm ci - name: Install Playwright Browsers run: npx playwright install --with-deps - name: Run Playwright tests run: npx playwright test - uses: actions/upload-artifact@v5 if: ${{ !cancelled() }} with: name: playwright-report path: playwright-report/ retention-days: 30Eso es todo. En serio. Copia este archivo, haz push, y tus tests corren en la nube.
¿Qué hace cada línea?
| Línea | Qué hace |
|---|---|
on: push/pull_request | Cuándo se ejecuta el pipeline (en cada push a main/develop, en cada PR) |
runs-on: ubuntu-latest | Usa un servidor Linux gratuito de GitHub |
actions/checkout | Descarga tu código del repositorio |
actions/setup-node | Instala Node.js |
npm ci | Instala dependencias de forma determinística (mejor que npm install en CI) |
playwright install --with-deps | Descarga los navegadores + dependencias del sistema operativo |
npx playwright test | Corre todos tus tests |
upload-artifact | Guarda el reporte HTML para que puedas descargarlo después |
if: !cancelled() | Sube el reporte incluso si los tests fallan (clave para debugging) |
Qué cambia cuando tus tests corren en CI
De repente, tus tests no son “algo que tú corres”. Son parte del proceso de desarrollo. El developer no puede mergear su PR si tus tests fallan. Eso cambia la conversación completamente: ya no es QA peleando por calidad — es la calidad integrada en el flujo.
Si el pipeline falla y no entiendes el log, pégale el error a la IA. Los errores de CI son repetitivos y bien documentados — es uno de los casos donde la IA brilla. También puedes pedirle que te genere el archivo YAML para tu setup específico.
3. Estrategia: qué automatizar y qué dejar manual
Esta es la pregunta que separa a un QA que escribe tests de un QA Automation Engineer: no automatices todo. Automatiza lo correcto.
La pirámide que sí funciona
No la pirámide teórica de los libros. La pirámide práctica de lo que realmente necesitas:
| Nivel | Qué automatizar | Cuántos tests | Velocidad |
|---|---|---|---|
| Smoke tests | Los 5-10 flujos críticos que si fallan, el negocio se para | 5-10 | Deben correr en menos de 5 min |
| Regression | Flujos que ya tuvieron bugs en producción | 20-50 | Corren en cada PR |
| Happy paths | Flujos principales completos | 10-30 | Corren en cada merge a main |
Lo que NO debes automatizar
La pregunta mágica
Antes de automatizar cualquier test, pregúntate:
¿Cuántas veces voy a ejecutar este test manualmente en los próximos 6 meses? Si la respuesta es menos de 10, probablemente no vale la pena automatizarlo.
Cómo priorizo yo
Mi proceso real para decidir qué automatizar primero:
- Reviso los bugs de los últimos 3 meses — si un flujo tuvo bugs en producción, se automatiza
- Identifico los tests que más duelen hacer a mano — los que toman más de 15 minutos manuales
- Pregunto al equipo — “¿qué flujo les da más miedo tocar?” Ese es el candidato número uno
- Descarto lo inestable — si la UI cambia cada sprint, lo dejo para después
El resultado no es “automatizar todo”. Es una lista priorizada de flujos donde la automatización ahorra tiempo real y reduce riesgo real.
Si quieres ir más profundo en métricas para medir si tu automatización realmente aporta, cuidado con la métrica más mentirosa en QA — el coverage no te dice lo que crees.
La hoja de ruta: meses 3-9
| Mes | Objetivo | Habilidad clave |
|---|---|---|
| 3-4 | Refactoriza tu suite a Page Object Model | POM, organización de código |
| 5 | Crea fixtures personalizados para setup/teardown | test.extend, reutilización |
| 6 | Implementa data-driven testing (mismos tests, diferentes datos) | Parametrización |
| 7 | Configura CI/CD con GitHub Actions | YAML, pipelines, artifacts |
| 8 | Define qué automatizar y qué dejar manual | Estrategia, pirámide de tests |
| 9 | Documenta tu framework para que otro QA pueda usarlo | README, convenciones |
Este plan es una guía, no una obligación. Algunos meses avanzarás rápido, otros te trabarás. Lo importante es no dejar de avanzar. Y recuerda: la IA te desbloquea cuando te trabas — úsala como tu par de programación constante.
¿Y después?
Ya tienes arquitectura. Ya tienes pipeline. Ya tienes estrategia. Pero un QA Automation Engineer completo necesita dominar más: testing de APIs, visual regression, hybrid testing — y saber cómo posicionarse profesionalmente.
Eso es exactamente lo que cubro en la Parte 3: el salto a QA Automation Engineer.
APIs, visual regression, hybrid testing — y cómo posicionarte como QA Automation Engineer con CV, LinkedIn y entrevistas. Leer la Parte 3 →
Academia sin Humo es una plataforma con 11 bugs ocultos donde puedes aplicar Page Object Model, fixtures y todo lo que viste en esta guía. Incluye un Kit de arranque con Playwright.