El Capítulo 1 del syllabus ISTQB dedica una página a listar los 7 principios del testing. Una página. Siete definiciones que caben en una servilleta.
Y sin embargo, cada uno de esos principios me costó al menos un incidente en producción entenderlo de verdad.
Aquí no vas a encontrar las definiciones del syllabus con ejemplos inventados. Vas a encontrar 7 historias reales — cada una terminó en un bug en producción, una conversación incómoda, o una lección que cambió cómo trabajo. Al final de cada historia, te cuento cómo se llama el principio, y te doy algo concreto para hacer el lunes a las 9am.
Cada sección tiene la definición oficial del principio al final. Para el examen, necesitas reconocer el nombre y la definición. Pero si entiendes la historia, no necesitas memorizar nada — lo vas a recordar.
1. El viernes que deployamos “sin bugs”
En un proyecto de gobierno, un sistema de nóminas. Miles de empleados dependían de ese cálculo para cobrar.
El equipo de desarrollo terminó un módulo nuevo. Lo probaron ellos mismos. “Funciona bien”, dijeron. QA no participó porque “no había tiempo”. El deploy fue un viernes a las 4pm.
El lunes, cientos de empleados no cobraron.
El bug estaba en un cálculo de horas extra que solo se activaba con jornadas de más de 12 horas. Nadie lo probó porque nadie trabaja 12 horas… excepto en turnos de fábrica. Y esa empresa tenía fábrica.
El equipo había probado el sistema. Encontraron 0 bugs. Y concluyeron: “no tiene bugs.”
No. Lo que encontraron fue: “no encontramos bugs con los casos que probamos.” Eso es completamente distinto.
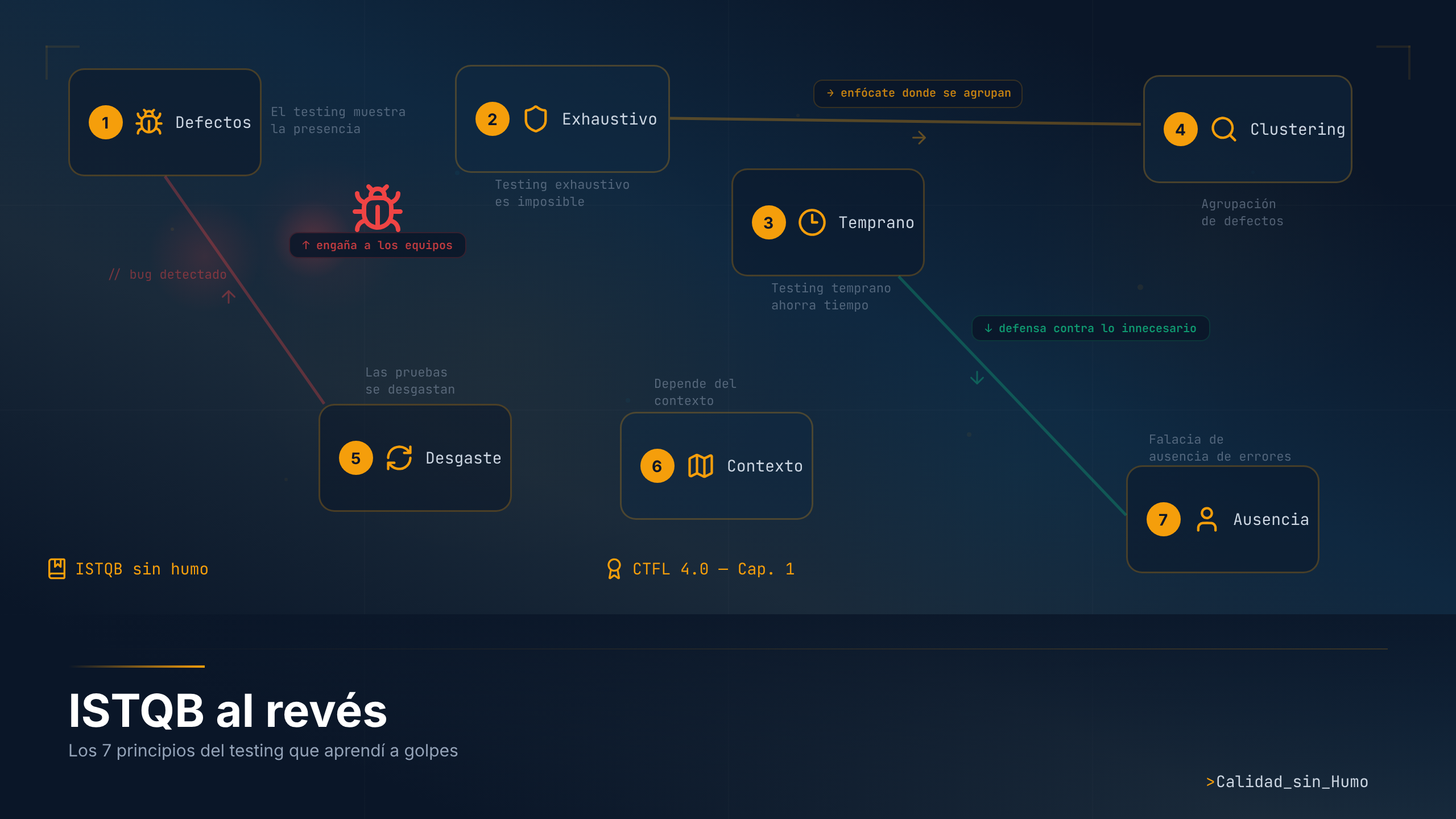
Principio 1: El testing muestra la presencia de defectos, no su ausencia.
Lunes a las 9am: La próxima vez que alguien diga “está probado, no tiene bugs”, pregunta: “¿Probado con qué datos? ¿Qué escenarios no se cubrieron?” No para ser pesado — para proteger al equipo.
2. “Prueba todo” — la instrucción más peligrosa en QA
En un proyecto fintech. Sprint cerrando el jueves. El PM me dice el miércoles a las 2pm: “Necesito que pruebes todo el módulo de pagos antes de mañana.”
“Todo” era: 4 métodos de pago × 3 monedas × 5 tipos de cuenta × 2 estados de usuario × 3 navegadores. Si sumas las combinaciones: 360 escenarios posibles. A 5 minutos cada uno: 30 horas de testing. Tenía 8 horas.
Si hubiera intentado “probar todo”, habría corrido por los escenarios superficialmente, sin profundidad, y habría entregado una falsa sensación de cobertura.
Lo que hice: prioricé. El método de pago más usado, el tipo de usuario más riesgoso, el navegador del 70% del tráfico. Cubrí 40 escenarios a fondo en vez de 360 por encima.
Encontré 3 bugs críticos en esos 40 escenarios. Los 320 restantes nunca se probaron. Y estuvo bien.
Principio 2: El testing exhaustivo es imposible.
Lunes a las 9am: Cuando te pidan “probar todo”, responde con una pregunta: “¿Qué es lo que más le duele al negocio si falla?” Eso define tus prioridades. Usa partición de equivalencia y análisis de riesgo para elegir qué probar — no la intuición.
Las técnicas del Capítulo 4 (partición de equivalencia, valores límite, tablas de decisión) existen precisamente porque no puedes probarlo todo. Te ayudan a elegir los casos que más bugs encuentran con menos esfuerzo. Si te interesa, las cubrimos con código en la serie ISTQB con código.
3. El bug de $50,000 que encontré sin ejecutar nada
En un sistema financiero. Me dieron un documento de requisitos de 40 páginas para un módulo de transferencias internacionales. Mi trabajo era escribir los casos de prueba.
En la página 23 encontré esta frase:
“El sistema debe validar que el monto no exceda el límite diario del usuario. Si el monto es mayor, se debe mostrar un mensaje de error.”
Dos párrafos después:
“Si el usuario tiene categoría Premium, no aplican límites de monto.”
Y tres páginas después:
“Todos los usuarios nuevos inician con categoría Premium durante los primeros 30 días.”
¿Lo ves? Cualquier usuario nuevo podía transferir cantidades ilimitadas durante 30 días. Sin verificación de identidad completa. Sin historial. Sin límites.
No ejecuté ni una línea de código. No abrí un navegador. Leí un documento y encontré un bug que, de llegar a producción, habría costado decenas de miles de dólares.
Ese bug se corrigió en el documento. El código se escribió bien desde el inicio. Costo de arreglar el bug: 1 hora de un analista editando un requisito. Costo si hubiera llegado a producción: incalculable.
Principio 3: Las pruebas tempranas ahorran tiempo y dinero.
Lunes a las 9am: Pide acceso a los documentos de requisitos antes de que el equipo empiece a codificar. Lee cada requisito buscando contradicciones, ambigüedades y casos que nadie consideró. No necesitas un entorno de pruebas para esto. Solo necesitas que te inviten al refinamiento.
4. El archivo donde vivían todos los bugs
En un portal B2B. Cuando implementé mutation testing, necesitaba elegir por dónde empezar. El proyecto tenía 50+ archivos de código.
Elegí un solo archivo de utilidades. Unas 370 líneas. 18 funciones. Era el corazón de la lógica de negocio — formateaba datos, validaba estados, calculaba permisos.
Escribí más de 90 unit tests solo para ese archivo. Mutation testing encontró 4 bugs reales que habían pasado code review:
Cuatro bugs. Un archivo. De los otros 50+ archivos, la mayoría eran componentes de UI con lógica trivial.
No fue casualidad. Los bugs se agrupan. Se acumulan en el código más complejo, más antiguo, más modificado. Si tienes tiempo limitado (y siempre lo tienes), enfoca tus tests donde los bugs viven — no donde es fácil probar.
Principio 4: Los defectos se agrupan (defect clustering).
Lunes a las 9am: Pregunta al equipo de desarrollo: “¿Cuál es el archivo que más miedo les da tocar?” Ese es donde deberías enfocar tus tests. Revisa el historial de git — los archivos con más commits y más bugs reportados son tus candidatos.
5. La suite de tests que nos daba confianza falsa
Heredé un proyecto con 80 tests automatizados. Todos pasaban. Dashboard en verde. El equipo estaba tranquilo.
Pero los usuarios seguían reportando bugs. Bugs que los tests “cubrían”.
Investigué. Resulta que los tests se habían escrito hacía 18 meses y nadie los había actualizado. El formulario de registro ahora tenía 3 campos nuevos. El flujo de checkout cambió completamente. Pero los tests seguían validando la versión anterior — y pasaban porque validaban cosas que ya no existían con selectores que ya no encontraban nada (y no fallaban, simplemente no verificaban).
Los tests eran como un antivirus desactualizado: te dice que estás protegido, pero no detecta las amenazas nuevas.
Principio 5: Los tests se desgastan (Tests wear out).
Si siempre corres los mismos tests, se desgastan — dejan de encontrar bugs nuevos. En versiones anteriores del syllabus este principio se llamaba “la paradoja del pesticida” (como un pesticida que usas tanto que los insectos se vuelven resistentes). En el CTFL 4.0 lo renombraron a algo más directo: los tests se desgastan. Necesitas actualizar, agregar escenarios nuevos, revisar qué ya no aplica.
Lunes a las 9am: Revisa tus tests automatizados. ¿Cuándo fue la última vez que fallaron y encontraron un bug real? Si la respuesta es “hace meses”, tienes tests desgastados. Agenda 30 minutos por sprint para revisar y actualizar tests existentes.
6. Lo que funciona en fintech no funciona en gobierno
En proyectos de gobierno, la prioridad era: que nadie pierda datos. La velocidad no importaba. Los usuarios esperaban. Lo que importaba era que el cálculo de nómina fuera correcto al centavo, que el registro civil no perdiera un nombre, que el sistema tributario no duplicara un pago.
Cuando empecé a trabajar en fintech, intenté aplicar el mismo enfoque. Revisión exhaustiva de datos, validaciones al milímetro, procesos lentos pero seguros.
Me dijeron: “El usuario se va si la página tarda más de 3 segundos.”
En fintech la prioridad era: rendimiento + seguridad. En healthtech después fue: privacidad + regulación. En verificación de identidad: precisión de la biometría.
Mismas técnicas de testing. Prioridades completamente distintas. Si hubiera aplicado el enfoque de gobierno en fintech, habría hecho tests perfectos para cosas que no importaban y habría ignorado lo que sí importaba.
Principio 6: El testing depende del contexto.
| Sector | Lo que más importa | Lo que puedes sacrificar |
|---|---|---|
| Gobierno | Precisión de datos, auditoría | Velocidad, UX moderna |
| Fintech | Rendimiento, seguridad, compliance | Perfección visual |
| Healthtech | Privacidad, regulación (HIPAA) | Features nuevos rápidos |
| ID Verification | Precisión biométrica, falsos positivos | Cobertura de edge cases raros |
Lunes a las 9am: Antes de escribir un test plan, pregunta: “¿En qué industria estamos y qué es lo que más le duele al negocio si falla?” La respuesta cambia todo: qué priorizas, qué técnicas usas, y qué nivel de cobertura es “suficiente”.
7. El sistema perfecto que nadie usaba
En un sistema de gestión educativa. Plataforma interna para universidades. La pasamos por QA completo: funcional, regresión, datos, permisos. Encontramos y corregimos todos los bugs. Zero defectos en producción.
El sistema era técnicamente impecable.
Seis meses después, la mayoría de los profesores seguía usando Excel. ¿Por qué? El flujo para cargar notas requería 14 clicks y 3 pantallas diferentes. En Excel eran 2 clicks y un copiar-pegar.
No tenía bugs. Tenía un problema peor: no resolvía el problema real del usuario.
Podríamos haber encontrado esto si hubiéramos hecho testing de usabilidad, si hubiéramos observado a un profesor usándolo, si hubiéramos preguntado “¿esto tiene sentido?” en vez de solo “¿esto funciona?”.
Principio 7: La falacia de la ausencia de errores.
Un sistema sin bugs que no resuelve el problema del usuario es un fracaso. El testing técnico es necesario pero no suficiente. Necesitas validar que el software resuelve lo que se supone que debe resolver.
Lunes a las 9am: La próxima vez que termines de testear una feature, siéntate al lado de alguien que va a usarla y observa. No le expliques nada. Solo mira. Si se confunde, se pierde, o tarda demasiado — encontraste un bug que ningún test automatizado va a detectar.
Los 7 principios en 30 segundos
Para el examen, para la entrevista, para cuando alguien te pregunte:
| # | Principio | En una frase |
|---|---|---|
| 1 | Presencia de defectos | Encontrar 0 bugs no significa que no existen |
| 2 | Testing exhaustivo imposible | No puedes probarlo todo — elige bien |
| 3 | Testing temprano | Arreglar un requisito cuesta 1 hora, arreglar producción cuesta miles |
| 4 | Agrupamiento de defectos | El 80% de los bugs vive en el 20% del código |
| 5 | Los tests se desgastan | Tests que nunca fallan ya no protegen |
| 6 | Depende del contexto | Lo que importa en fintech no es lo que importa en gobierno |
| 7 | Ausencia de errores | Sin bugs + nadie lo usa = fracaso |
Te dan un escenario y te preguntan qué principio aplica. Por ejemplo: “Un equipo ejecuta la misma suite de regresión cada sprint y reporta que no encuentra defectos nuevos.” La respuesta es el principio 5 (los tests se desgastan). Si entiendes las historias de arriba, estas preguntas se responden solas.
Lo que no dice el syllabus
Estos 7 principios están escritos desde 2005. Son atemporales porque son fundamentales. Pero hay algo que el syllabus no dice y que yo aprendí en 15 años:
Los principios no funcionan solos. Son un sistema. El principio 2 (no puedes probarlo todo) te obliga a usar el principio 4 (enfócate donde se agrupan los bugs). El principio 3 (testea temprano) es la mejor defensa contra el principio 7 (construir algo que nadie necesita). El principio 5 (los tests se desgastan) es la razón por la cual el principio 1 (0 bugs ≠ sin bugs) engaña a tantos equipos.
Cuando los ves como sistema — no como lista — dejan de ser definiciones para memorizar y se convierten en una forma de pensar.
Y eso es exactamente lo que no te enseña ningún curso de preparación.