Estás en refinamiento. El equipo lleva tres meses con SDD. La spec de hoy entra al pipeline mañana — code generator, test generator, validator, todo automatizado. Levantas la mano y haces una pregunta sencilla.
“¿Quién decidió que el code generator y el test generator usen el mismo prompt base?”
Silencio. El arquitecto te mira. El dev también. Nadie tiene la respuesta. El pipeline lleva tres meses funcionando. Funcionando bien, según el dashboard de velocity — los puntos del sprint subieron 60%. Pero nadie audita el pipeline en sí. Lo trataron como infraestructura, no como código. Como herramienta, no como arquitectura.
Esa pregunta tuya, hecha en el refinamiento de un martes a las 10 de la mañana, es la que va a destapar un problema que se acumuló silenciosamente durante 60 features. Y no es el único.
Hoy va la Parte 2.
Antes de seguir — el recap
El miércoles publiqué la Parte 1 de esta serie con los dos roles más visibles donde tu posición cambia con SDD: el dev y el PO. Si no la leíste, este artículo va a tener más sentido después.
Antes de la Parte 1, dos lecturas que te dan el marco completo: Spec-Driven Development: si la IA escribe los tests, ¿para qué nos pagan a los QA? — donde abrí la pregunta hace un mes — y la guía paso a paso con GitHub Spec Kit que la acompañó.
Hoy cubrimos los dos roles donde el cambio queda invisible durante más tiempo. Y donde el daño es mayor cuando se descubre.
La frase de ayer la traigo de vuelta. Si te la sabes, mejor:
El QA dejó de ser el último filtro. Ahora es el primero.
El dev y el PO los ves todos los días. Sus problemas con SDD aparecen rápido — un PR con bug, una US ambigua. El arquitecto trabaja en una capa que el resto del equipo no toca, y sus problemas se acumulan durante meses sin que nadie note nada. El Scrum Master (SM) mide el sprint con métricas que SDD vuelve mentirosas — y nadie le avisó.
Acá es donde te necesitan más. Y donde menos te piden.
Frente al arquitecto: arquitectura por acumulación
Antes, cuando un equipo agregaba una feature, había una decisión arquitectónica implícita: ¿cómo se cachea esto? ¿qué patrón de manejo de errores usamos? ¿cómo loggeamos? ¿cómo accedemos a la base? El arquitecto definía las reglas, el equipo las aplicaba, y la coherencia del sistema se mantenía porque había humanos pensando en cada implementación.
Con SDD esa cadena se rompe.
La IA genera el código desde la spec. La spec describe el comportamiento funcional. Casi nunca describe la arquitectura. Entonces la IA toma decisiones arquitectónicas sola, en cada feature, sin saber que las está tomando. Una feature cachea en memoria porque la spec mencionó “rápido”. La siguiente cachea en Redis porque el prompt de esa generación pasó cerca de un ejemplo con Redis. La tercera no cachea porque la spec no dijo nada.
Multiplica eso por 60 features en tres meses.
Sin guardrails arquitectónicos explícitos en cada spec, la IA elige patrones random. El sistema termina con 4 estrategias de cache distintas, 3 formas de serializar errores, 2 maneras de hacer queries — y todos los tests pasan. Porque cada feature, aislada, funciona. El problema solo aparece cuando miras el sistema completo y descubres que ya no tiene arquitectura. Tiene 60 micro-arquitecturas pegadas con cinta.
Te lo cuento con un ejemplo que vas a reconocer.
Imagina un equipo de e-commerce con tres meses usando SDD. El dashboard de velocity está en récord. Sale a producción una feature de “carrito persistente entre sesiones” y empieza a haber tickets raros: usuarios reportan que el carrito a veces aparece vacío y a veces no. Cuando vas a investigar descubres que esa feature cachea en memoria del servidor — y como hay tres instancias detrás del load balancer, el carrito está en una memoria pero no en las otras. Y por qué cachea en memoria si el resto del sistema usa Redis? Porque la spec dijo “respuesta rápida” y la IA interpretó “memoria es lo más rápido”.
Eso es un bug arquitectónico, no un bug funcional. Y los tests pasaron porque corrieron contra una sola instancia.
Repite el escenario 15 veces, una por feature, durante tres meses. Tienes un sistema donde la deuda técnica no es la consecuencia de equipos apurados — es la consecuencia del modelo de desarrollo.
El pipeline de agentes ES la nueva arquitectura
Pero hay un nivel todavía más profundo, y casi nadie lo está mirando.
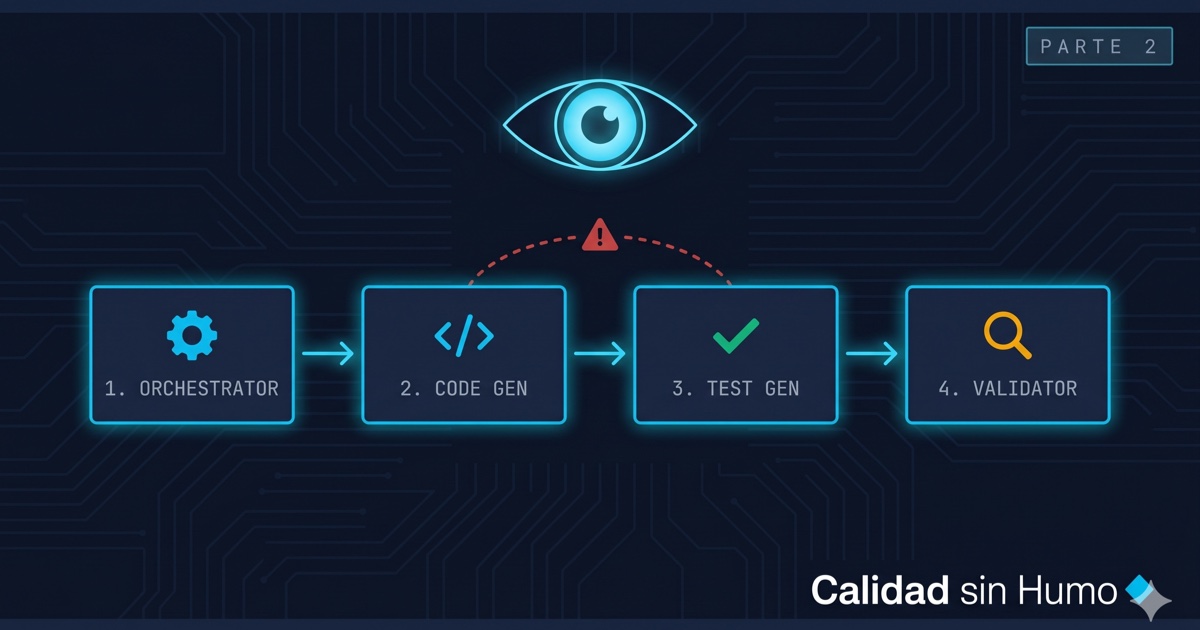
El pipeline SDD típico tiene cuatro piezas: un orchestrator que coordina, un code generator que produce código, un test generator que produce tests, y un validator que verifica que código y tests coincidan. Suena prolijo. Y funciona.
Hasta que te haces la pregunta del refinamiento: ¿qué pasa si el code generator y el test generator usan el mismo prompt base con la misma spec?
Pasa exactamente lo de ayer. La trampa circular, pero ahora a nivel infraestructura. Los tests verifican lo que el código hace porque ambos artefactos nacen del mismo cerebro mirando la misma fuente. No es un bug del dev — es un bug del pipeline. Y el pipeline lo diseñó alguien hace tres meses sin que ningún QA estuviera mirando.
Cualquier sistema que genere código y tests automáticamente desde una misma fuente, sin separación de cerebro, tiene la trampa circular incorporada por diseño. Auditar features sin auditar el pipeline es como hacer code review línea por línea sin haber leído nunca el framework subyacente.
Tu nuevo trabajo: auditar arriba, no solo al lado
Antes te sentabas con el dev y revisabas el código de su feature. Eso sigue existiendo — pero es la parte más visible y más pequeña de tu trabajo.
Ahora trabajas en dos capas nuevas:
Capa 1: auditar el pipeline. Si tu equipo adoptó SDD, alguien diseñó la cadena de agentes. Tienes que entender quién diseña qué, qué prompts usa cada agente, qué fuente comparten, dónde está el riesgo de la trampa circular. Esto es trabajo conjunto con el arquitecto — pero la pregunta de “¿quién audita el orchestrator?” en la mayoría de equipos te toca a ti, porque eres la única persona del equipo cuyo oficio se construyó sobre ver lo que falla.
Capa 2: auditar los guardrails arquitectónicos en cada spec. Una spec sin guardrails es una invitación a la arquitectura por acumulación. Tienes que asegurar que cada spec, antes de entrar al pipeline, traiga los siete guardrails explícitos. No los inventas tú — los recibes del arquitecto. Pero tú los exiges en cada spec.
La calidad de la spec dejó de ser un nice-to-have funcional. Pasó a ser una métrica de arquitectura. Una spec sin guardrails es deuda técnica esperando acumularse. Y la única manera de evitar la acumulación es exigir los guardrails en la auditoría pre-spec.
Los 7 guardrails arquitectónicos que toda spec debe traer explícitos
Cuando recibas una spec para auditar, además de los 7 huecos funcionales de ayer, busca estos 7 guardrails arquitectónicos. Si alguno falta, la spec no entra al pipeline.
1. Estrategia de cache. Cuándo guardar una copia rápida de un dato para no volver a buscarlo en la base cada vez. La spec debe decir dónde se guarda esa copia (memoria del servidor, Redis compartido, base), cuánto tiempo vive antes de pedir una versión fresca, qué evento la borra o la refresca, y qué hace el sistema cuando muchos usuarios piden el mismo dato al mismo tiempo y la copia no existe todavía. Sin esto en la spec, la IA elige cualquier esquema en cada feature — y terminas con una feature cacheando en memoria del servidor, otra en Redis, otra sin cache. Todas pasan los tests, ninguna está alineada.
2. Patrón de manejo de errores. Qué tipos de excepciones puede lanzar, qué códigos HTTP devuelve, qué estructura tiene el payload de error, qué se loggea cuando falla. Sin esto, cada endpoint serializa errores a su manera y el frontend tiene que parsear tres formatos distintos.
3. Patrón de queries a base de datos. Cómo cada feature trae los datos cuando hay muchos registros relacionados. Hay tres caminos típicos: una sola query que combine las dos tablas en el mismo viaje a la base (un join), traer todos los registros que necesitas en un solo lote (batch read), o hacer una query inicial y después una por cada resultado — el camino malo, conocido como N+1 (pedir 100 usuarios y después disparar 100 queries más, una por cada uno, para traer sus pedidos). La spec debe decir cuál de los tres es aceptable. La IA, sin restricción, escribe el código que cumple el test. El test pasa con dos registros y muere con dos mil.
4. Estrategia de observability. Qué se loggea, qué métricas se exponen, qué traces se emiten, qué nivel de detalle. Sin esto, debuggear un bug de producción se vuelve arqueología.
5. A qué módulo pertenece (su bounded context). En sistemas grandes, cada parte tiene su propia responsabilidad bien delimitada — el módulo de pagos no debe leer ni escribir directamente en el de inventario, el de notificaciones no toca el de usuarios. Esos límites se conocen como bounded contexts en arquitectura de dominio. La spec debe decir explícitamente qué módulos puede tocar esta feature, qué APIs internas tiene permiso de consumir, qué eventos publica o lee. La IA no entiende esos límites si no se los explicas — y empieza a acoplar módulos que jamás se deberían tocar.
6. Contratos hacia afuera. Qué APIs expone (con versión), qué APIs consume (con versión), qué pasa si una API consumida cambia su contrato. Esto es lo primero que se rompe cuando el sistema crece y nadie audita los contratos.
7. Presupuesto de rendimiento (performance budget). Los límites que la feature no puede exceder en producción. Tres números concretos: cuánto tiempo máximo puede tardar una respuesta del endpoint (latencia — por ejemplo, no más de 300ms), cuántos requests por segundo debe poder atender sin caerse (throughput), y cuánta memoria del servidor puede ocupar el módulo bajo carga (memory footprint). Y además: qué hace el sistema cuando uno de los tres se excede — ¿devuelve error, encola las peticiones, degrada el servicio a una versión más simple? Sin esto, la primera feature que va a producción y se rompe bajo carga te explica por qué los tests pasaron — corrieron con 2 usuarios, no con 2000.
Esos siete guardrails no los inventas tú feature por feature. Los recibes del arquitecto, una sola vez, como contrato del módulo. Tu trabajo es exigirlos en cada spec, antes de que entre al pipeline.
Frente al Scrum Master: la velocity miente
El SM mide el sprint con métricas que llevan décadas funcionando: velocity, burndown, lead time, throughput. Lo que ningún libro de Scrum cuenta es que esas métricas asumen un cuello de botella que SDD acaba de eliminar: el tiempo de implementación.
Antes, una user story bien definida tomaba tres días de implementación, uno de tests y uno de QA. Cinco días. Si tu equipo bajaba ese número era una victoria.
Con SDD, la misma US ya implementada y con tests generados puede salir del pipeline en cuatro horas. La velocity numérica explota — los puntos del sprint suben 200%, 300%, a veces más. El dashboard del SM se ilumina. La gerencia celebra.
Y mientras tanto, los bugs caros tres sprints después también empiezan a subir.
Cuando el tiempo de implementación deja de ser el cuello de botella, la velocity deja de medir la salud del equipo. Mide la cantidad de features que cruzaron un pipeline — no si cruzaron bien. Equipos que celebran velocity 300% con SDD están midiendo lo equivocado y no lo saben todavía.
El SM tiene un problema técnico nuevo que no estaba en el libro: las métricas que usaba para detectar problemas dejaron de detectarlos. Necesita métricas nuevas. Necesita una conversación nueva en cada ceremonia. Y necesita aliados — porque la presión de “estamos rápidos, no frenes” va a venir desde arriba en cuanto el dashboard se ilumine.
Tu nuevo trabajo: ser ese aliado.
Las 3 ceremonias que se transforman — y la única que sigue igual
Tres ceremonias del sprint cambian de raíz cuando el equipo trabaja con SDD. Una sigue exactamente igual. Si las identificas, puedes ayudar al SM a recalibrar el ritmo del equipo en una sola retro.
Refinamiento. Antes era una conversación de estimación y aclaración de US. Ahora es el evento más crítico del sprint — porque el pre-spec audit del QA y del arquitecto vive ahí. Si el refinamiento se hace apurado, todo lo que sale del pipeline después está contaminado.
Antes de SDD: conversación entre dev y PO. El QA participa “si tiene tiempo”. Se estima en puntos, se aclaran dudas obvias, se asume que el dev va a resolver lo demás durante la implementación. La US sale del refinamiento con 70% de claridad — el 30% restante se descubre escribiendo el código.
Con SDD: conversación entre PO, dev, QA y arquitecto. El QA aplica los 7 huecos funcionales (de ayer) y los 7 guardrails arquitectónicos (de hoy). El arquitecto valida el bounded context y el contrato. La US no sale del refinamiento hasta tener 100% de claridad — porque después del refinamiento, el pipeline ejecuta sin humanos en el medio. El 30% que antes se descubría durante implementación, ahora se acumula como deuda técnica para siempre.
Daily. Antes el equipo reportaba “estoy implementando X” o “estoy bloqueado en Y”. Ahora el vocabulario cambia. Si el SM no entiende el nuevo lenguaje, deja de saber dónde está cada persona del equipo.
Antes de SDD: “ayer terminé el endpoint de usuarios, hoy arranco con el módulo de pagos.” El SM sabe que la persona está escribiendo código de producción. La unidad de progreso es el código.
Con SDD: “ayer terminé la spec del módulo de pagos, hoy entra al pipeline.” O: “ayer auditamos la spec con el arquitecto, encontramos un drift en el bounded context, hoy reescribimos.” La unidad de progreso ya no es el código — es la claridad de la spec. El SM tiene que aprender el vocabulario nuevo o pierde visibilidad de dónde está el sprint.
Retro. Antes la retro buscaba problemas usando lo que pasó en el sprint que acaba de terminar. Ahora los problemas más importantes — los bugs arquitectónicos por acumulación, la deuda técnica generada por specs sin guardrails, la trampa circular — no aparecen en el sprint que acaba de terminar. Aparecen tres sprints después. El SM tiene que cambiar las métricas que llegan a la retro o la retro deja de detectar lo que importa.
Antes de SDD: métricas del sprint que cierra — velocity, bugs encontrados, lead time, qué fue bien, qué fue mal. La conversación se centra en cómo mejorar la siguiente iteración.
Con SDD: métricas nuevas — % de specs que entraron al pipeline con guardrails completos, % de features con drift arquitectónico detectado cross-feature, bugs caros que aparecen en producción y rastreo de qué spec los originó, señales tempranas de trampa circular en el pipeline. La conversación deja de ser solo sobre “este sprint” y empieza a ser sobre la salud sistémica del modelo de desarrollo.
Sprint Review. Esta sigue exactamente igual. El stakeholder no necesita saber que cambiaste el pipeline interno. Necesita ver que el sistema cumple lo que se prometió. Punto. Cualquier intento del equipo de “explicarle SDD al cliente” en el review es ruido — y suele venir cuando algo del proceso anda mal y el equipo busca excusas.
El stakeholder evalúa el producto, no el proceso. Si la calidad del producto bajó con SDD, eso aparece en el review. Si la velocity subió pero los bugs caros también, eso aparece en el review. El SM defiende el review como espacio donde el método no se discute — solo el resultado.
Tu nuevo trabajo: traducirle el cambio al SM
El SM rara vez tiene background técnico profundo. Sabe Scrum. No necesariamente sabe qué es un orchestrator de agentes, un guardrail arquitectónico o una trampa circular. Si esperas que él descubra solo que sus métricas dejaron de medir lo importante, te puede tomar meses — meses que el equipo va a pasar acumulando deuda técnica con la complicidad accidental del proceso.
Tu trabajo es darle el vocabulario y las métricas nuevas. No en una clase teórica — en la próxima retro. Llega con los datos. Muestra una feature donde la trampa circular se manifestó. Muestra el drift arquitectónico entre dos módulos generados con tres semanas de distancia. Muestra el número real de bugs caros del último mes versus el número que tenía el equipo seis meses atrás.
Y proponle, ceremonia por ceremonia, las preguntas nuevas.
Plantilla: 3 preguntas por ceremonia
Para cada ceremonia transformada, llega con tres preguntas que recalibran lo que se mide. Si el SM las adopta, el equipo entero empieza a ver el sistema con el ojo correcto.
Refinamiento — las 3 preguntas
-
¿Esta US tiene los 7 huecos funcionales cerrados y los 7 guardrails arquitectónicos explícitos? Si la respuesta es no, no sale del refinamiento.
-
¿Quién es el dueño de cada guardrail arquitectónico aplicable a esta US? El QA y el arquitecto firman el pre-spec audit antes de que entre al pipeline.
-
¿Esta US toca un módulo donde ya detectamos drift arquitectónico en sprints anteriores? Si sí, agregar al refinamiento una revisión cross-feature antes de entrar al pipeline.
Daily — las 3 preguntas
-
¿En qué fase del ciclo SDD está cada persona — escribiendo spec, auditando spec, esperando pipeline, auditando output del pipeline?
-
¿Hay alguna spec esperando entrar al pipeline con guardrails incompletos? Si sí, ese es el verdadero blocker del sprint — no la velocity.
-
¿Alguien encontró señales de trampa circular en el output del pipeline esta semana? Esas señales suben al SM y al arquitecto inmediatamente.
Retro — las 3 preguntas
-
¿Cuántas specs entraron al pipeline esta iteración con guardrails 100% completos versus parciales? Esta métrica reemplaza, parcialmente, a la velocity.
-
¿Cuántos bugs caros del último mes pudimos rastrear a una spec específica? Y de esos, ¿cuántos eran prevenibles con los 7 huecos o los 7 guardrails aplicados correctamente?
-
¿Hay drift arquitectónico cross-feature que se acumuló este mes y nadie lo nombró antes? Esta pregunta evita el escenario de la deuda técnica silenciosa.
Estas tres preguntas, por ceremonia, no son una imposición teórica. Son lo que tu nuevo trabajo ya hace todos los días — solo necesitas llevarlas al espacio donde el SM mide la salud del equipo. Si lo haces, las próximas retros van a sentirse profundamente distintas. Si no lo haces, el SM va a seguir mirando una velocity falsa hasta que el daño sea inocultable.
Lo que viene el sábado
El miércoles cubrimos al dev y al PO. Hoy al arquitecto y al SM. Tienes el mapa completo de tu nueva posición frente a los cuatro roles principales del equipo. Pero un mapa sin recorrido es solo papel.
El sábado cierra la serie con la guía: el playbook completo para arrancar el primer ciclo SDD multi-rol con tu equipo. Paso a paso, anti-patrones incluidos, sin teoría. Es lo que vas a usar la primera vez que te toque liderar — o defender — el primer ciclo SDD real de tu equipo. Y si tu equipo todavía no adoptó SDD pero ves que viene, es la conversación que vas a llevar al próximo sprint planning para entrar bien preparada.
SDD no te reemplazó. Te promovió. Pero la promoción solo se consolida cuando ocupas la nueva posición en los cuatro roles — y cuando otros del equipo te ven hacerlo. La calidad de un equipo entero adoptando SDD depende, más que nunca, del QA que entendió primero qué cambió.
Si la Parte 1 te resonó y la Parte 2 también — el sábado vas a tener todo lo que necesitas para arrancar. Nos vemos.